python 使用 struct 把数据变成字节流 |
您所在的位置:网站首页 › according to 用法 › python 使用 struct 把数据变成字节流 |
python 使用 struct 把数据变成字节流
|
1 struct 的作用:
可以将数据按照指定的格式转成字节流, 2 struct 里面的函数 2.1 struct.pack(format, v1, v2, ...):返回一个包含值v1、v2、 ... 根据格式字符串format打包的字节对象。参数必须与格式所需的值完全匹配。 2.2 struct.pack_into(format, buffer, offset, v1, v2, ...):根据格式字符串format打包值v1 , v2 , ...并将打包的字节写入从位置offset开始的可写缓冲区缓冲区。请注意,偏移量是必需的参数。 2.3 struct.unpack(format, buffer):根据格式字符串format从缓冲缓冲区(大概是由 打包)解包。结果是一个元组,即使它只包含一个项目。缓冲区的字节大小必须与格式要求的大小相匹配,如.pack(format, ...)calcsize() 2.4 struct.unpack_from(format, /, buffer, offset=0):根据格式字符串format,从位置offset开始从缓冲区解包。结果是一个元组,即使它只包含一个项目。从位置offset开始的缓冲区大小(以字节为单位)必须至少是格式所需的大小,如 所反映的那样。calcsize() 2.5 struct.iter_unpack(format, buffer):根据格式字符串format从缓冲区缓冲区中迭代解包。此函数返回一个迭代器,它将从缓冲区读取相同大小的块,直到其所有内容都已被消耗。缓冲区的字节大小必须是格式所需大小的倍数,如 所反映的。calcsize() 2.6 struct.calcsize(format):返回与格式字符串format对应的结构体(以及由此产生的字节对象)的大小 。pack(format, ...) 这个是3.4之后的新功能,注意format 不能随意输入 字节顺序、大小和对齐方式默认情况下,C 类型以机器的本机格式和字节顺序表示,并在必要时通过跳过填充字节来正确对齐(根据 C 编译器使用的规则)。 或者,可以使用格式字符串的第一个字符来指示打包数据的字节顺序、大小和对齐方式,如下表所示: Character Byte order Size Alignment @ native native native = native standard none big-endian standard none ! network (= big-endian) standard none 格式化字符格式字符有以下含义;考虑到它们的类型,C 和 Python 值之间的转换应该是显而易见的。'Standard size'列是指使用标准大小时打包值的大小(以字节为单位);也就是说,当格式字符串中的一个开始'','!'或 '='。使用本机大小时,打包值的大小取决于平台。 Format C Type Python type Standard size Notes x pad byte no value c char bytes of length 1 1 b signed char integer 1 (1), (2) B unsigned char integer 1 (2) ? _Bool bool 1 (1) h short integer 2 (2) H unsigned short integer 2 (2) i int integer 4 (2) I unsigned int integer 4 (2) l long integer 4 (2) L unsigned long integer 4 (2) q long long integer 8 (2) Q unsigned long long integer 8 (2) n ssize_t integer (3) N size_t integer (3) e (6) float 2 (4) f float float 4 (4) d double float 8 (4) s char[] bytes p char[] bytes P void * integer (5) 在 3.3 版更改:添加了对'n'和'N'格式的支持。 在 3.6 版更改:添加了对'e'格式的支持。 Notes: 的'?'转换码对应于_Bool由C99定义的类型。如果此类型不可用,则使用char. 在标准模式下,它总是用一个字节表示。 当尝试使用任何整数转换代码打包非整数时,如果非整数有一个__index__()方法,则在打包之前调用该方法将参数转换为整数。 在 3.2 版更改:添加了__index__()对非整数方法的使用。 的'n'和'N'转换码只适用于本机的大小(选择为默认或与'@'字节顺序字符)。对于标准大小,您可以使用适合您的应用程序的任何其他整数格式。 对于'f','d'和'e'转换码,填充表示使用IEEE 754 binary32,binary64或binary16格式( 'f','d'或'e'分别地),而不管由所述平台中使用的浮点格式的。 该'P'格式字符仅适用于本地字节顺序(选择为默认或与'@'字节顺序字符)。字节顺序字符'='根据主机系统选择使用小端或大端排序。struct 模块不会将此解释为本机排序,因此'P'格式不可用。 IEEE 754 binary16“半精度”类型是在IEEE 754 标准的 2008 年修订版中引入的。它有一个符号位、一个 5 位指数和 11 位精度(显式存储 10 位),并且可以表示近似 精度6.1e-05和6.5e+04全精度之间的数字。C 编译器并不广泛支持这种类型:在典型机器上,无符号短整型可用于存储,但不能用于数学运算。有关更多信息,请参阅有关半精度浮点格式的维基百科页面。 以上内容参考python 官网教程地址链接 基本知识了解完之后开始使用, demo 说明struct 的使用 demo1 将数字3转成1个字节流从上面的字符表格中可以看到转成1个字节流的是B 和b import struct # 把3转成1个字节 num_a = struct.pack("B", 3) print(num_a) print(struct.pack("b", 3)) # 将字符流解包 num_b = struct.unpack("B", num_a) print(num_b)运行打印的结果如下:
从上面的字符表格中可以看到转成1个字节流的是H和h import struct # 把3转成1个字节 num_a = struct.pack("H", 3) print(num_a) print(struct.pack("h", 3)) # 将字符流解包 num_b = struct.unpack("H", num_a) print(num_b)打印结果如下:
打印结果如下:
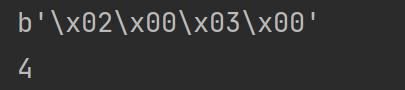
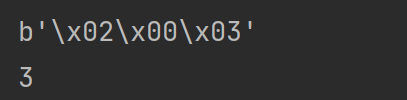
--------------------------------待思考问题----------------------------- 多个字节组合在一起,字节感觉变的没有规律了,比如1和字节和2个字节组合在一起是4个字节, 目前不知道为啥? 比如 print(struct.pack("BH", 2, 3)) print(struct.calcsize("BH"))打印结果: 这个时候4个字节 修改一下 print(struct.pack("HB", 2, 3)) print(struct.calcsize("HB"))打印结果:
这个时候3个字节, 我是被这个弄晕了,不知道为啥。 |



【本文地址】